
一句话:让 Claude Code 在「需要一张图」的时候,自己把图画了——不用人去 ChatGPT 里画好再贴回来,也不用为它单独开一个
OPENAI_API_KEY。

1. 初心:别让 agent 卡在「等人画图」
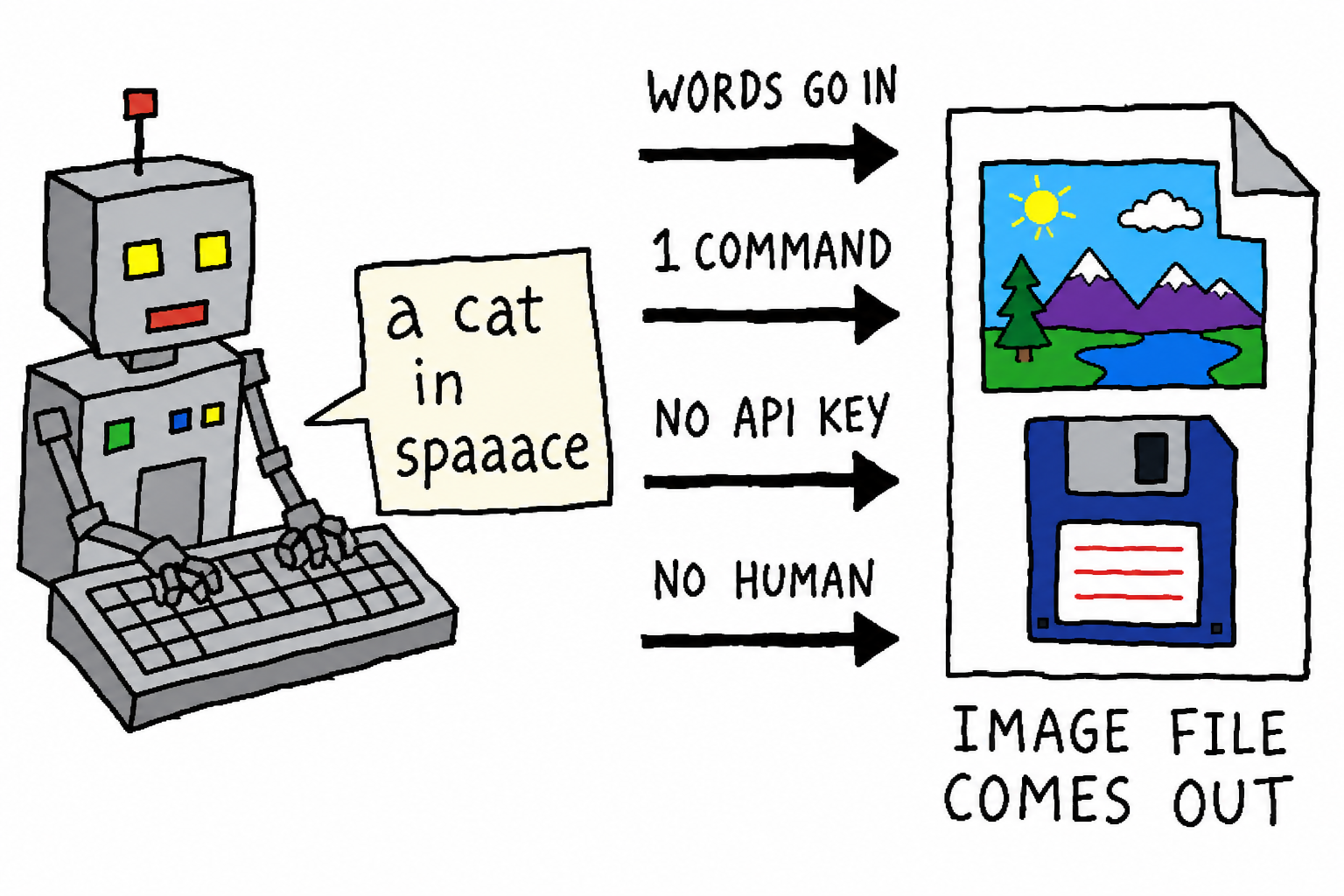
让 Claude Code 这样的 agent 真正端到端地做项目,你迟早撞到同一堵墙:它需要一张图。
一个 README 的 hero banner、一个 app 的占位图标、一张落地页的配图、一份原型的 mockup、几张 sprite……代码它能写,图它画不出来。于是流程断在这里:
- 要么给它配一个
OPENAI_API_KEY走官方图像 API——额外的钥匙、额外的计费、额外的配置,还和你的 ChatGPT 订阅是两套账; - 要么你亲自打开 ChatGPT,把图生成好,再下载、贴回项目里——agent 停在那儿干等,「自主」二字荡然无存。
chatgpt-imagegen 的初心就是把这堵墙拆了:agent 缺图,自己造,零人工接手。 用的是你本来就有的 ChatGPT 订阅,不需要 API key,不需要起任何网关服务。
2. 一条命令,agent 就能用
它是一个单文件、零依赖的 Python CLI(只用标准库),装成 skill 之后,agent 直接调:
chatgpt-imagegen "a watercolor cat sitting on a windowsill" -o assets/cat.png
# -> assets/cat.png (1,344,804 bytes)
为 agent 优化的细节都在:--quiet 时 stdout 只输出保存路径(方便 OUT=$(...) 接管),进度条走 stderr;每个后端有跨进程并发锁,agent 批量 fan-out 也不会把账号打爆。
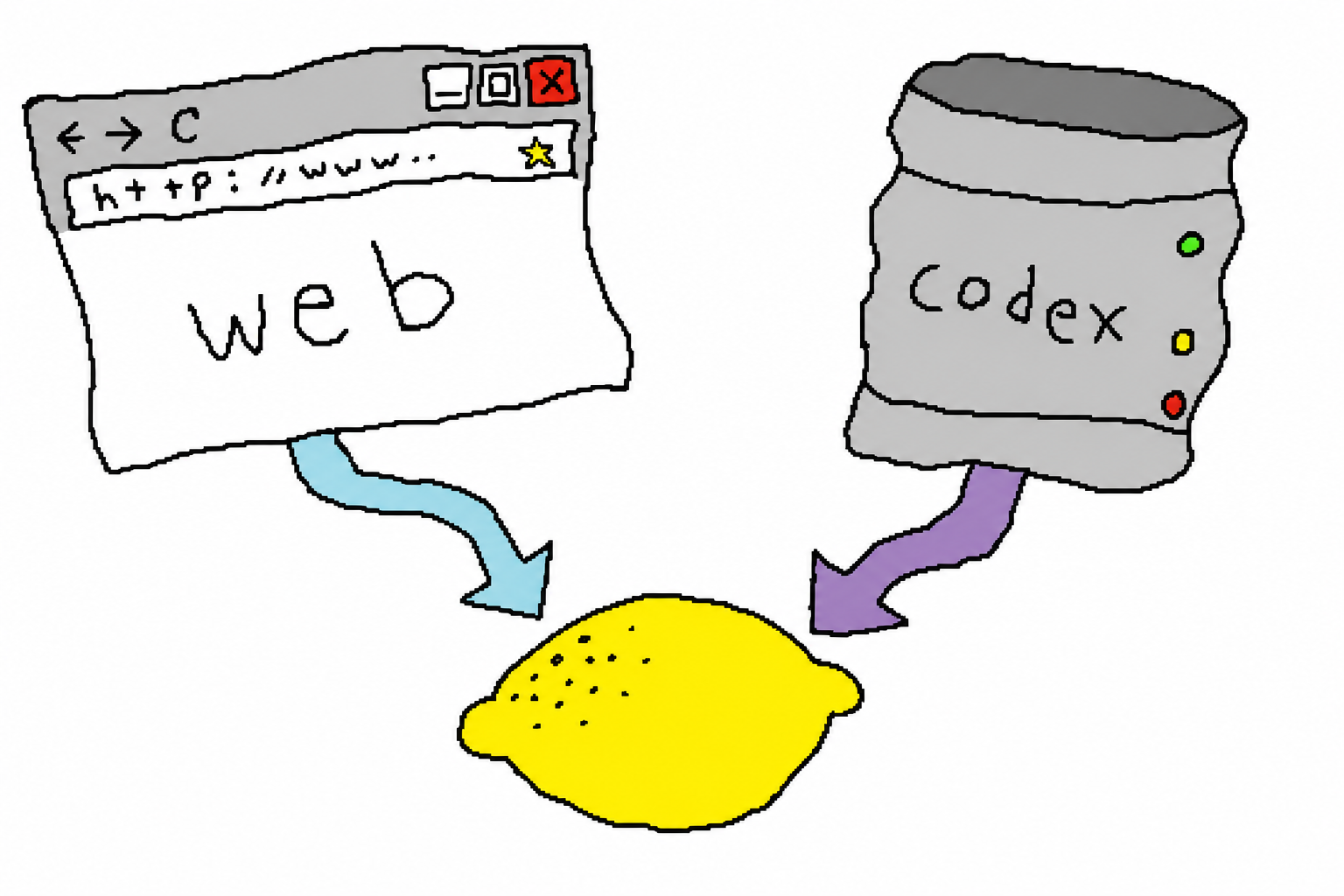
3. 核心原理:两个后端,两个计费桶
这是整个项目最关键的设计。同一个 ChatGPT 订阅,其实有两个能出图的入口,花的是两个不同的额度桶:
| 后端 | 怎么出图 | 花哪个额度 | 适合谁 |
|---|---|---|---|
web(默认) | 用 chrome-use 驱动你已登录的真实 Chrome,在普通对话里出图 | 对话额度,不碰计量的 Codex-usage | 笔记本/台式机,开着登录好的 Chrome;免费账号也能用 |
codex | 无头 POST 到 backend-api/codex/responses,复用 ~/.codex/auth.json | Codex-usage(计量桶,通常是你想省的那个) | 服务器/无头 agent 机器,没有浏览器 |
默认是 auto:先试 web(省 Codex 额度),只有当浏览器不可用(没装 chrome-use / 没登录)时才回退到 codex。这条策略的意思是——能不花计量额度,就不花。
为什么 web 后端非得开一个真浏览器?
直觉上,「在普通对话里出图」似乎直接 POST 那个 backend-api/* 接口就行。我们真去试了一发裸客户端(只带 accessToken、不带任何浏览器凭证),结果挺反直觉——防线其实是三层,硬点不在你以为的地方:
| 层 | 裸 headless 能不能过 | 说明 |
|---|---|---|
Cloudflare cf_clearance | 能过 | 实测本机裸 urllib 打 sentinel/chat-requirements 直接 200。CF 是 IP 信誉/启发式判定,不是硬墙——换个差 IP 才可能被挑战 |
| Sentinel PoW | 能(离线复刻) | hashcash 式纯计算题,sdk.js 算法已知,能自己算;但随 OpenAI 轮换而脆 |
| Turnstile | 过不了 | 交互式的 Cloudflare 反机器人 token,裸客户端造不出来,只能由真实浏览器现场产出 |
所以真正卡死「无浏览器直连」的,不是 Cloudflare,也不是 PoW,是 Turnstile。而且就算想「借浏览器只取这个 token、其余 headless」也行不通:Turnstile token 单次、短时、绑定本次挑战——你等于每个请求都得开一次浏览器,「无浏览器」直接自相矛盾。
这就是 web 后端非得驱动一个真实、已登录的 Chrome、而不是直接调接口的全部原因,也是为什么它必须用 chrome-use(真实 Chrome 连接),而不是普通无头 driver。想彻底不开浏览器,现成的路只有 codex 后端——代价是认 Codex 额度。
4. image 模型,效果是真的好
省额度不等于降画质——web 后端走的就是 ChatGPT 网页里那个原生图像生成器,效果跟你在 app 里手打一样。下面三张都是这个工具真实产出的(文生图 + 图生图各有):
| 文生图 | 图生图:把水彩猫改成金光油画 | 图生图:把 logo 贴上木牌 |
|---|---|---|
 |  |
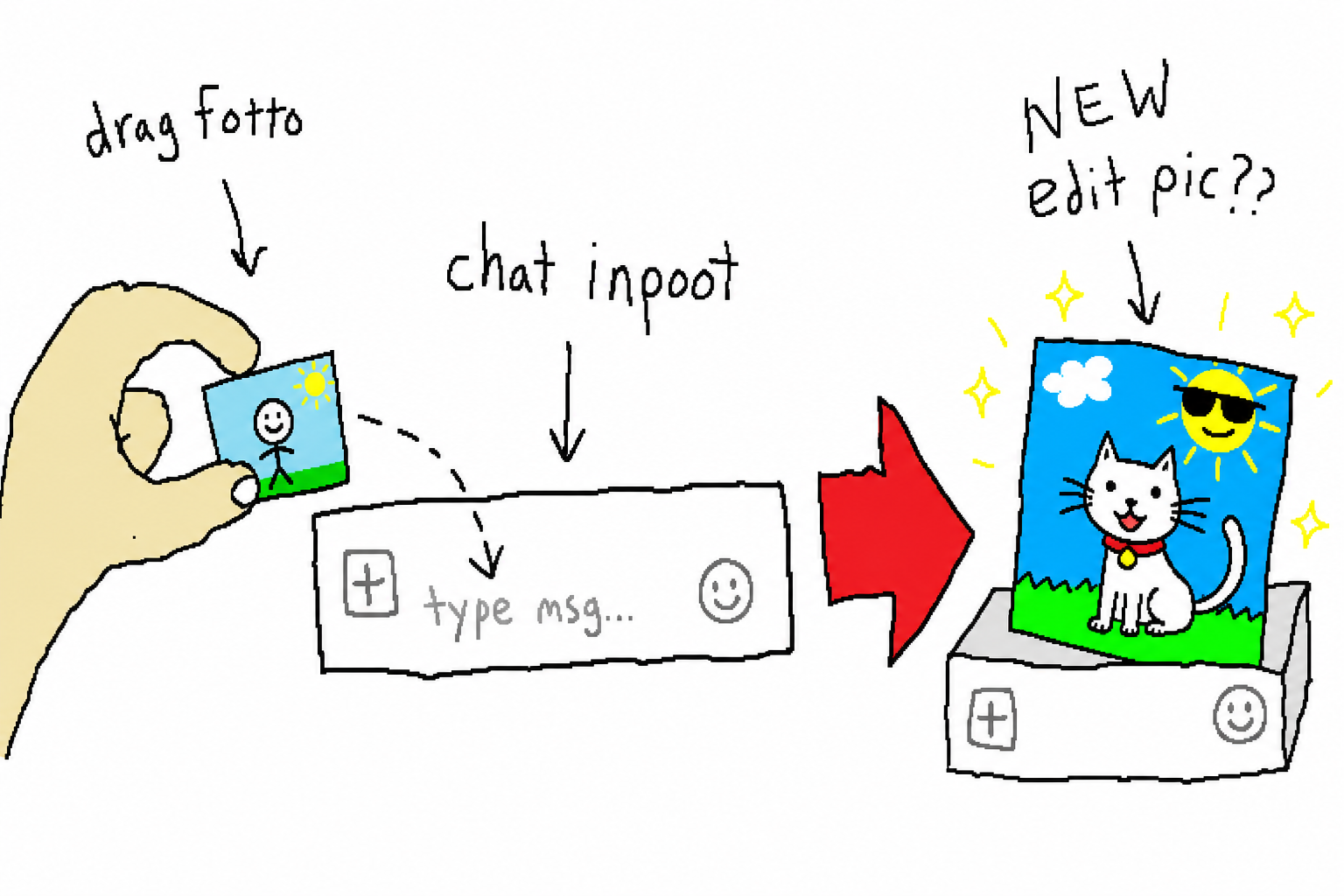
5. 图生图:给它一张参考图
传一张参考图(-i),它就改图而不是从零画——和你把图拖进 ChatGPT 输入框让它重绘是同一回事。两个后端各有实现:
- web:把参考图经
chrome-use upload注入到 composer 的标准<input type="file">,再发编辑指令——零站点适配,不消耗 Codex 额度; - codex:把参考图作为
input_image内容块塞进请求,强制触发图像工具。
# 把一张 logo 改成赛博朋克霓虹招牌
chatgpt-imagegen "把它做成赛博朋克霓虹招牌" -i logo.png -o neon.png
一个有意思的原理坑:怎么认出「生成的那张图」
web 后端是在驱动一个真实页面,所以它得从 DOM 里把生成的图认出来,这里有三个反直觉的点:
- 新版 ChatGPT 的图走
backend-api/estuary/content,不再是老的oaiusercontent; - 图生图时,你上传的参考图会在用户气泡里以一个全新 src 回显——一不小心就把「你自己上传的原图」当成结果抓走;
- 生成图是一张独立的图像卡片,并不包在助手消息元素里。
所以正确的判定是:在 <main> 里找匹配图床域名的新图,但排除掉任何属于用户气泡的图。

6. 为 agent 而生的设计思路
把这些原则连起来,就是这个项目的设计取向:
- 单文件、零依赖、纯标准库——agent 拉过去就能跑,没有
pip install、没有虚拟环境、没有常驻进程; - 可作为 skill 安装——
npx skills add leeguooooo/chatgpt-imagegen -g,Claude Code / Codex / Cursor 等都能直接调; - 默认省钱——auto 模式优先走不计量的 web;真要快或在无头机器上,再用 codex;
- 结果落进工作区——agent 拿到的就是一个保存好的文件路径,直接进 repo;
- 对话自动归档——web 后端把每次出图的对话归进一个 ChatGPT Project(默认
imagegen),不污染你的历史。
一句话:它不是给人用的图像工具套了个 CLI,而是从一开始就为「agent 自己缺资源自己造」这件事设计的。
7. 上手
# 作为 skill(推荐,给 agent 用)
npx skills add leeguooooo/chatgpt-imagegen -g
# 或者独立 CLI(零依赖,单文件)
git clone https://github.com/leeguooooo/chatgpt-imagegen
然后对你的 agent 说一句「给 README 画个 hero 图」就行——剩下的它自己来。
工具仓库:chatgpt-imagegen | 背后的浏览器自动化引擎:chrome-use。
题外话:这篇文章里那些故意画烂的涂鸦原理图,和上面那几张好看的示例图,全是这个工具自己出的。烂的是讲解风格,好看的是它真实的本事——这反差本身,就是它最好的演示。
评论
评论发布后会立即公开,如触发规则可能被审核下架。