
先抛结论:这套系统跑在一个月费 5 美元起的 Cloudflare Workers 计划上,多区域压测时读路径轻轻松松顶到 86 万+ RPS、worker 零错误,而且——根本没压垮,是发压端先到了瓶颈,读的真实天花板还在更高处。
这事儿听起来离谱,但它不靠堆机器,靠的是一个反直觉的架构判断。先说说为什么会有这套东西。
现成的边缘 KV 很好用,但它不是为「1 秒就过期、还要全球一致」的数据设计的。当业务是逐球开奖——每开出一个球就要写一次结果,有效期只有 1 秒,高峰每秒三千多次写、读量再翻几十上百倍——边缘 KV 那种「最终一致、秒级传播」的特性,恰好踩在我们最不能容忍的点上。
于是我们在 Cloudflare Workers + Durable Objects 上,自己搭了一个秒级强一致的热点 KV。这篇想聊的不是「我们用了多少组件」,而是一个反直觉的核心思路,以及那些到今天还没收敛干净的过渡设计——好的架构不是没有烂代码,而是知道烂在哪、为什么还留着、往哪收。
一、把瓶颈当成强一致性的来源
Durable Object 最让人「嫌弃」的一点是:它是单线程的。每个对象同一时刻只处理一个请求,请求排队。直觉上你会想方设法绕开它、把它打散。
但换个角度:正因为单线程、串行,它天然就是强一致性的——同一个 key 的所有读写都在同一个对象里排成一条线,没有竞态、没有"读到半个写"。秒级开奖最怕的就是不一致。所以我们的选择不是绕开单线程,而是认下它,把它当成唯一真相源,然后在它前面叠一整套防御,让真正打到它的流量小到它扛得住。
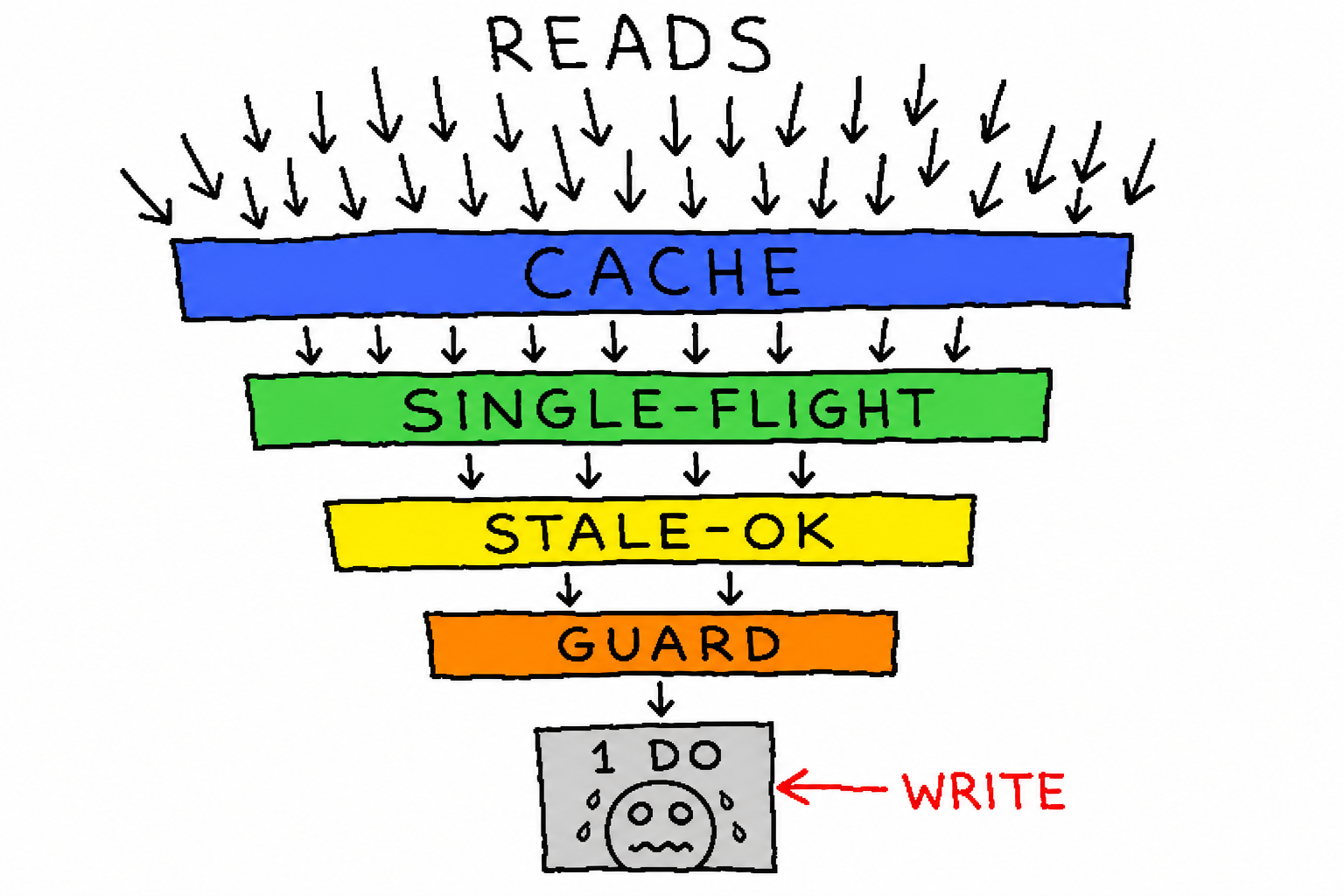
从上往下,每一层都在「吃掉」一部分流量:
- 边缘缓存(
caches.default):每个 Cloudflare PoP 一份共享缓存。绝大多数读在离用户最近的机房就被命中,根本不回源。 - single-flight(请求合并):同一个 isolate 内,对同一个 key 的并发回源被一个
Map<key, Promise>合并成一次真正的回源——这是整套设计里最关键的一层,后面单说。 - Stale-While-Revalidate:缓存过期不等于不可用。先把略旧的值返回给用户,后台异步刷新。用户永远不等。
- null 占位:对"不存在的 key"和"过载时拿不到的 key"写一个短 TTL 的空占位,避免同一个缺失 key 被反复打穿到 DO(缓存击穿/雪崩)。
- 503 背压:真过载时,优雅地返回 503 +
Retry-After,而不是把 DO 拖死。
再加两个小而关键的决定:
双 TTL 分离。「逻辑新鲜度 TTL」(开奖键 1 秒)管的是"这个值多久算旧、要不要刷",「存储 TTL」管的是"底层留多久"。两者解耦,才能既保证秒级新鲜、又不让底层频繁失效。
冷热分离。热点 key 按哈希走专属分片(
open-shard-<hash>),和海量普通 key 的负载均衡分片彻底隔开,热点的风暴不会溅到别人。
二、一次写崩盘,和一层思路的修复
设计再漂亮,也得被真实流量教育一次。某次开奖,热点写路径集体翻车:写不进、读超时。复盘下来,根因是教科书式的——读洪流踩踏单线程 DO,写挤不进去。
开奖那一瞬,前端海量用户同时来读同一个结果 key。当时缓存回源没有合并,成千上万个读请求各自去敲同一个单线程 DO,把它的请求队列彻底塞满;逐球写到了 DO 门口,排在长队最后面,迟迟轮不到——于是写超时、失败。
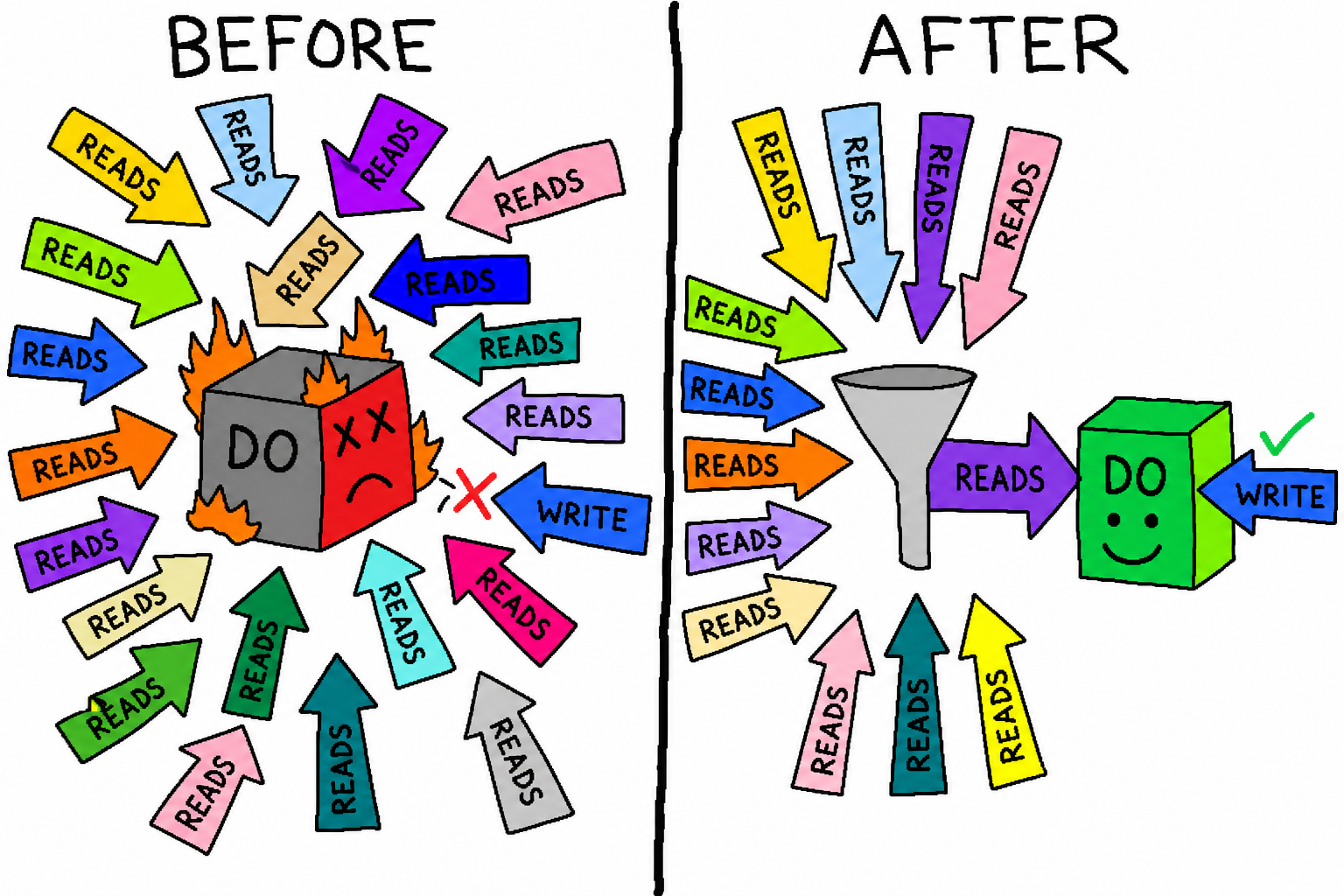
修复其实只是补齐了漏斗里的那一层——single-flight:同一个 isolate 内,发现已经有一个针对该 key 的回源在飞,后来者就直接复用那个 Promise,而不是再去敲一次 DO。对一个被几万人同时轮询的热点 key,回源量可以从"几万次"塌缩到"一次"。配合把开奖键的逻辑 TTL 收到 1 秒,既挡住风暴又保证秒级新鲜。
| 指标(同负载、同 key、各持续 5 分钟) | 修复前 | 修复后 |
|---|---|---|
| SET 写成功率 | 4% | 100% |
| 写后「5 秒内读到新值」 | 6% | 99.7% |
| 最慢一次写 | ~17 秒 | 亚秒级 |
| DO 过载错误 | 有 | 0 |
更说明问题的是事后一次真实开奖:边缘请求峰值约 32 万/分钟、DO 调用峰值约 7.2 万/分钟——比事故当晚的负载还高出一大截——DO 错误为 0。不是同等负载下勉强持平,是更高负载下零失败。一层请求合并,撑住了整个读路径。
三、5 美元的底座,86 万 RPS 还没摸到的天花板
这套系统跑在 Cloudflare Workers 的付费计划上——每月 5 美元起步。没有自建集群、没有常驻机器、没有运维待命,按用量在边缘计费。生产常态流量(高峰逐球写每秒数千、读量再放大几十倍)下,账单基本就贴着这个底座浮动。
便宜的关键不在"省",而在读 RPS 和成本被解耦了。还记得那个漏斗吗——绝大多数读在离用户最近的边缘缓存就被命中,真正穿透到那个按调用计费的单线程对象的流量,小到可以忽略。所以读量涨几十倍,底层调用和账单几乎不动。
那上限在哪?我们用多区域分布式压测,从全球 5 个区域同时对单 key 发起读洪流,往死里打:
读路径持续顶住约 85 万 RPS、峰值约 88 万 RPS,全程 worker 错误为 0。同一时间真正落到单线程 DO 的调用只有每分钟一两万次——因为读早被边缘缓存吸走了。读吞吐拉到几十万每秒,DO 几乎没感觉。
而且根本没压垮:我们发多少压,边缘几乎就服务多少,曲线还在往上、是压测端先到了瓶颈。
换句话说,86 万 RPS 不是这套架构的天花板,只是我们当晚发压能力的天花板,真实上限还在更高处。一个 5 美元的底座,加上一套"把读尽量挡在边缘"的纵深防御,换来的是几乎线性可扩、又便宜得不像话的读吞吐。这不是什么魔法,是把账算在了对的地方。
四、零成本的可观测性
这套系统至今没开重型日志。但"事后能不能查清当时发生了什么",并不等于"有没有开日志"。我们靠的是两路本来就持久存在的信号:平台侧的分析数据(请求数、对象调用数、错误数,逐分钟,保留约 30 天),和业务侧每次 KV 操作推送到群里的卡片(成功/失败/慢操作,永久留存)。
事故复盘、修复验证、乃至"主开奖时段到底干不干净",全都是从这两路持久数据里对出来的,一行额外日志都没开。可观测性的第一性原理是"信号要持久、可追溯",而不是"日志要开得多"。把业务关键事件做成持久卡片,比无差别打日志更省、更准。
五、诚实复盘:那些还没收敛的设计
到这里都在讲"思路有多对"。但真实的系统里,永远有一半是历史包袱和半成品。把它们藏起来不叫架构好,敢摊开、知道往哪收,才叫。
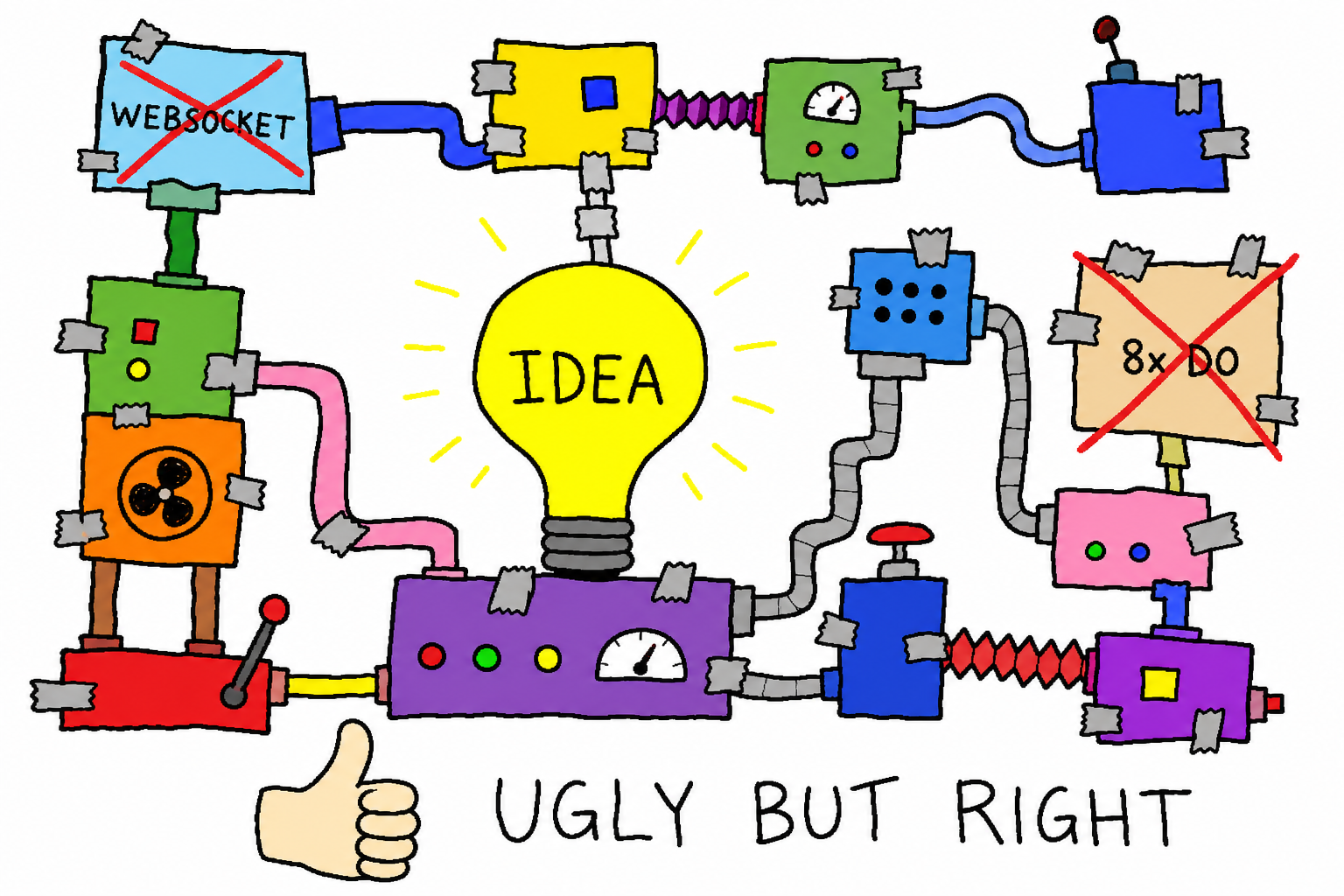
- 遗留的多实例 DO + WebSocket 架构。更早一版用 8 个中心 DO 实例 + WebSocket 长连接撑两千多并发,复杂度极高、运维心智负担重。现在的"高并发 KV + 缓存"路线把它整体替掉了,但代码里还留着尾巴,正在逐步删。
- 每个热点 key 单 DO = 该 key 的单点。冷热分离的代价是:一个开奖 key 只对应一个 DO 实例。平台偶尔会驱逐/重启/重新落位这个对象,那一瞬间在途的读连接会被掐断(
Network connection lost)。它和负载无关、是基础设施抖动,但我们一开始没把它当"瞬时可重试错误",于是它直接暴露成用户侧的硬错误。补救是读路径对这类瞬时连接错误重试一次(读幂等,亚秒级重试就能打到已恢复的对象)。 - 告警没分级。很长一段时间,客户端发来一个格式非法的 key(4xx,纯属对方拼错),和 DO 真过载(5xx),推的是同一种红色告警。4xx 是"别人发错了"、5xx 才是"我们挂了",混在一起就是误报刷屏。后来才按状态码分级,红卡只留给 5xx。
- 一堆"能用就行"的糙实现。用关键字(key 里含
open/current)来识别热点类型、用一条白名单正则校验 key 合法性、D1 双写与历史聚合半成品……都谈不上优雅,但在各自的阶段都解决了当时的问题。
六、好的思路,到底是什么
回头看,这套系统真正"对"的地方,没有一个是某个炫技的组件。它对在几个朴素的判断上:
认清单线程边缘对象的物理本质——它慢、它串行、它会被重启,但它强一致。不跟它的本质对抗,而是顺着它设计。
然后是四个动作:用分层缓存吸收读、用合并消解并发、用降级换可用、用持久的业务信号代替昂贵的可观测性。
过渡设计不可耻。一个系统从"两千并发的 WebSocket 集群"演进到"一层请求合并扛住三十万每分钟",中间必然踩着一堆将就和半成品。工程的常态不是一步到位,而是方向判断对 + 持续诚实地收敛。丑的部分会一个个被划掉,亮的那盏灯一直亮着——这就够了。
评论
评论发布后会立即公开,如触发规则可能被审核下架。