
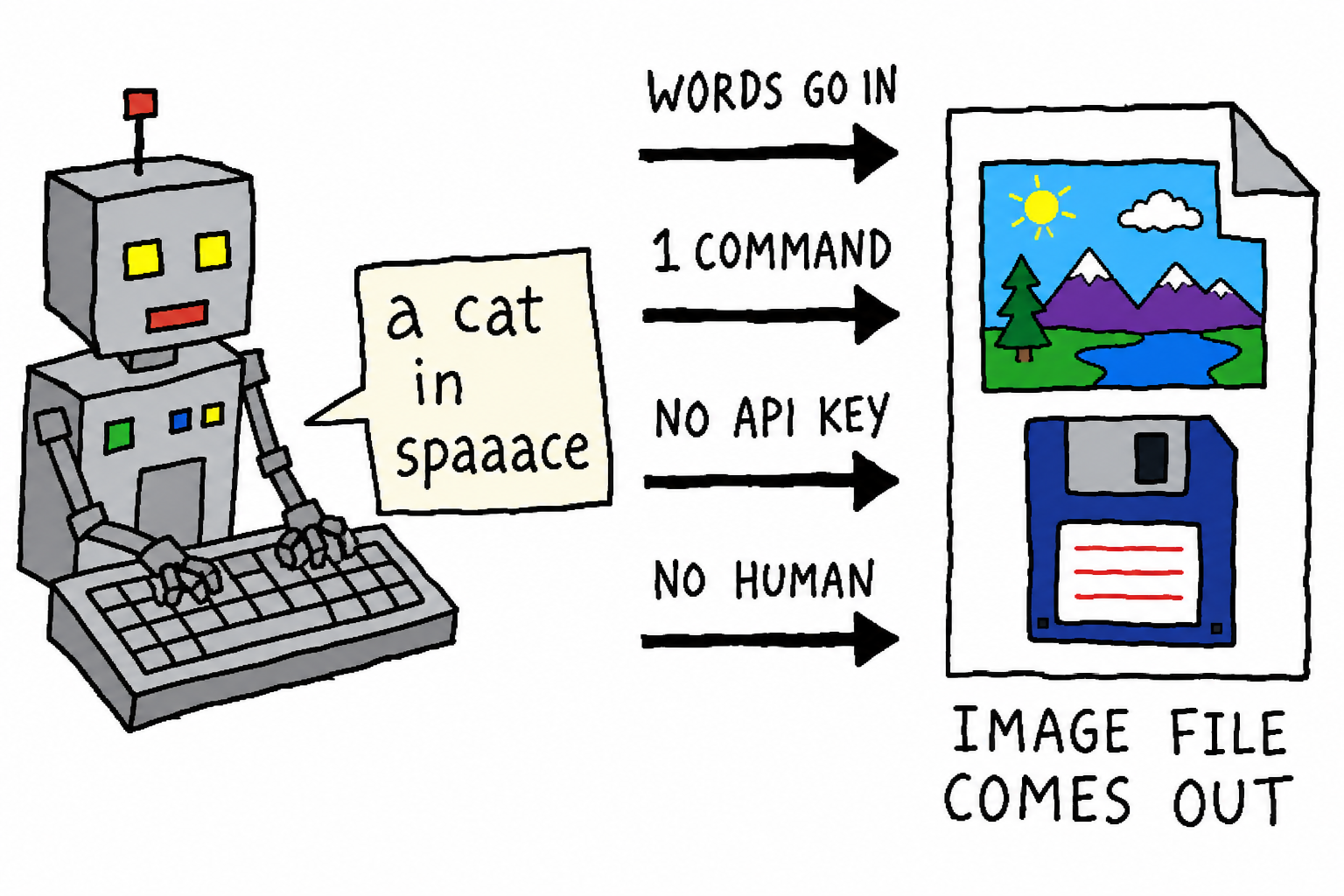
一言でいうと、Claude Code が「画像が1枚必要」になったときに、**自分でその画像を描く**ようにするものです。人間が ChatGPT で画像を作ってから貼り戻す必要もなければ、そのためだけに
OPENAI_API_KEYを別途用意する必要もありません。

1. 初心:agent を「人が絵を描くのを待つ」ところで止めない
Claude Code のような agent に、プロジェクトを本当にエンドツーエンドでやらせようとすると、いずれ同じ壁にぶつかります。画像が1枚必要になるのです。
README の hero banner、app の仮アイコン、landing page の挿絵、prototype の mockup、いくつかの sprite……コードは書けても、絵は描けない。するとフローはここで途切れます。
- あるいは
OPENAI_API_KEYを渡して公式の画像 API を使わせる——追加の鍵、追加の課金、追加の設定が必要で、しかもあなたの ChatGPT サブスクとは別会計です。 - あるいはあなたが自分で ChatGPT を開き、画像を生成し、ダウンロードしてプロジェクトに貼り戻す——agent はその場で待ちぼうけ、「自律」の2文字は跡形もなくなります。
chatgpt-imagegen の初心は、この壁を取り払うことです。agent が画像を必要としたら、自分で作る。人手による引き継ぎはゼロ。 使うのは、あなたがもともと持っている ChatGPT サブスクです。API key は不要、gateway service を立てる必要もありません。
2. コマンド一発で、agent が使える
これは**単一ファイル・依存ゼロ**の Python CLI(標準ライブラリのみ使用)で、skill として導入すれば、agent はそのまま呼び出せます。
chatgpt-imagegen "a watercolor cat sitting on a windowsill" -o assets/cat.png
# -> assets/cat.png (1,344,804 bytes)
agent 向けに最適化した細部も揃っています。--quiet のとき stdout は**保存先パスだけ**を出力(OUT=$(...) で受け取りやすい)、進捗バーは stderr へ。さらに各 backend にはプロセス横断の並行ロックがあり、agent が batch fan-out してもアカウントを叩き潰しません。
3. 核心原理:2つのバックエンド、2つの課金バケット
これはプロジェクト全体でいちばん重要な設計です。同じ ChatGPT サブスクでも、実は2つの画像生成エントリがあり、消費するのは**別々の上限バケット**です:
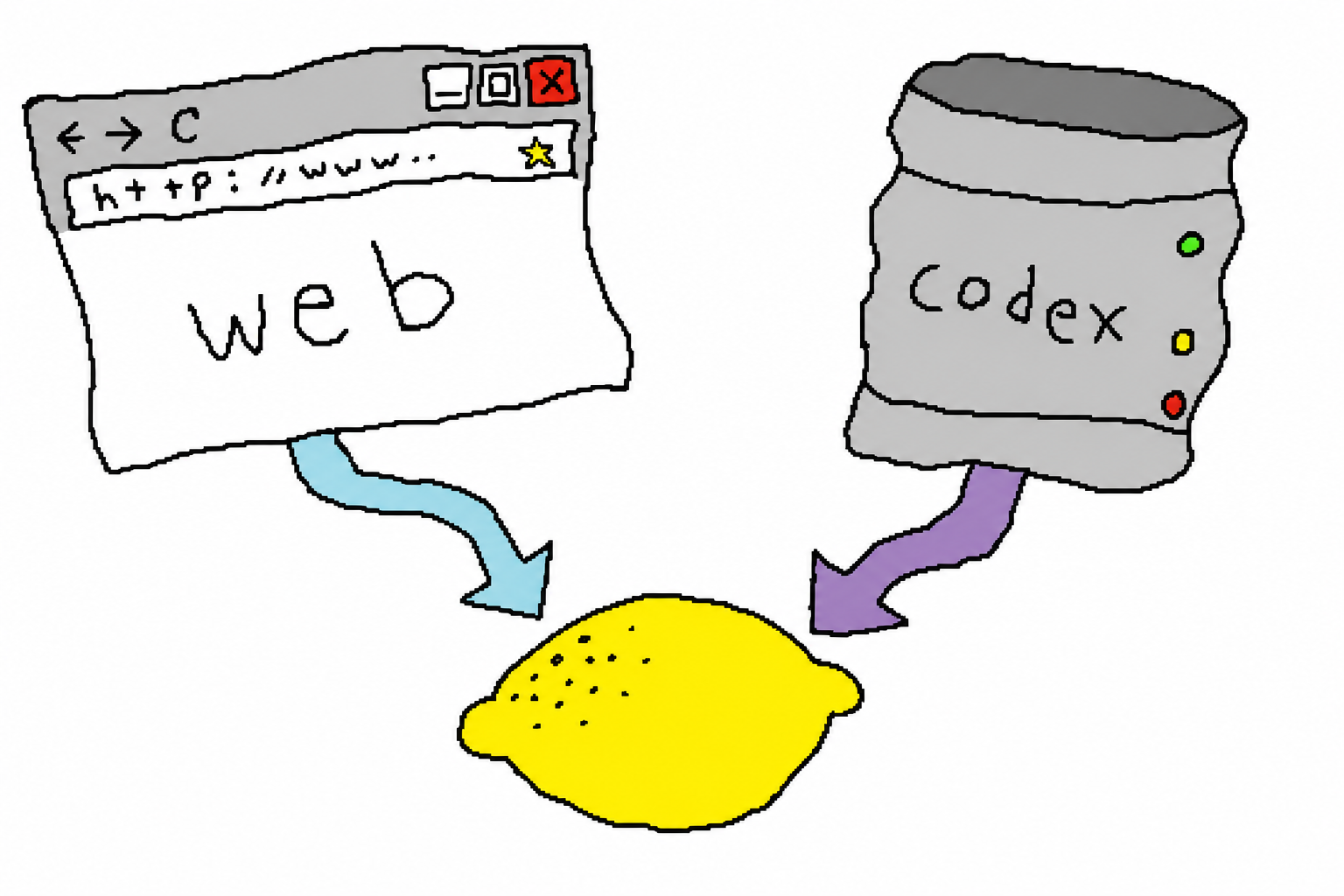
| バックエンド | どう画像を出すか | どの枠を使うか | 向いている人 |
|---|---|---|---|
web(デフォルト) | chrome-use で**ログイン済みの本物の Chrome**を操作し、通常の会話の中で画像を出す | 会話枠、計量の Codex-usage には**触れない** | ノートPC/デスクトップ、ログイン済み Chrome を開いている環境;無料アカウントでも使える |
codex | ヘッドレスで backend-api/codex/responses に POST し、~/.codex/auth.json を再利用 | Codex-usage(計量バケット、たいてい節約したい方) | サーバー/ヘッドレス agent 機、ブラウザなし |
デフォルトは auto:まず web を試す(Codex 枠を節約)、ブラウザが使えない(chrome-use が未導入 / 未ログイン)場合だけ codex にフォールバックします。この戦略の意味は——計量枠を使わずに済むなら、使わない。
なぜ web バックエンドには本物のブラウザが必要なのか?
直感的には、「通常会話で画像を出す」なら、その backend-api/* インターフェースへ直接 POST すればよさそうです。でも、それはできません:コンシューマー版のこれらのインターフェースは、Cloudflare の人間確認 + sentinel の proof-of-work の奥にいるためです——ページ内の sentinel/sdk.js がその場で token を計算し、裸の bearer リクエストはエッジで弾かれます。
この関門を通れるのは、ログイン済みの本物のブラウザだけです。これが web バックエンドが Chrome を操作し、直接 API を呼ばない理由のすべてであり、また通常のヘッドレス driver ではなく chrome-use(本物の Chrome 接続で、反 bot 検証を通過できる)を使わなければならない理由でもあります。
## 4. image <ruby>模型<rt>もけい</rt></ruby>、<ruby>効果<rt>こうか</rt></ruby>は<ruby>本当に<rt>ほんとうに</rt></ruby>いい
<ruby>枠<rt>わく</rt></ruby>を<ruby>節約<rt>せつやく</rt></ruby>することは<ruby>画質<rt>がしつ</rt></ruby>を<ruby>下げる<rt>さげる</rt></ruby>ことではありません——web バックエンドが<ruby>使っている<rt>つかっている</rt></ruby>のは、ChatGPT のウェブ<ruby>画面<rt>がめん</rt></ruby>にあるあのネイティブ<ruby>画像生成器<rt>がぞうせいせいき</rt></ruby>そのものなので、<ruby>効果<rt>こうか</rt></ruby>は app で<ruby>手打ち<rt>てうち</rt></ruby>するのと<ruby>同じ<rt>おなじ</rt></ruby>です。<ruby>下<rt>した</rt></ruby>の 3 <ruby>枚<rt>まい</rt></ruby>はいずれもこのツールの**<ruby>実際<rt>じっさい</rt></ruby>の<ruby>出力<rt>しゅつりょく</rt></ruby>**です(<ruby>文<rt>ぶん</rt></ruby>から<ruby>画像<rt>がぞう</rt></ruby> + <ruby>画像<rt>がぞう</rt></ruby>から<ruby>画像<rt>がぞう</rt></ruby>の<ruby>両方<rt>りょうほう</rt></ruby>あり):
| <ruby>文<rt>ぶん</rt></ruby>から<ruby>画像<rt>がぞう</rt></ruby> | <ruby>画像<rt>がぞう</rt></ruby>から<ruby>画像<rt>がぞう</rt></ruby>:<ruby>水彩<rt>すいさい</rt></ruby>の<ruby>猫<rt>ねこ</rt></ruby>を<ruby>金色<rt>きんいろ</rt></ruby>の<ruby>光<rt>ひかり</rt></ruby>の<ruby>油絵<rt>あぶらえ</rt></ruby>に | <ruby>画像<rt>がぞう</rt></ruby>から<ruby>画像<rt>がぞう</rt></ruby>:logo を<ruby>木<rt>き</rt></ruby>の<ruby>看板<rt>かんばん</rt></ruby>に<ruby>貼る<rt>はる</rt></ruby> |
| --- | --- | --- |
|  |  |  |
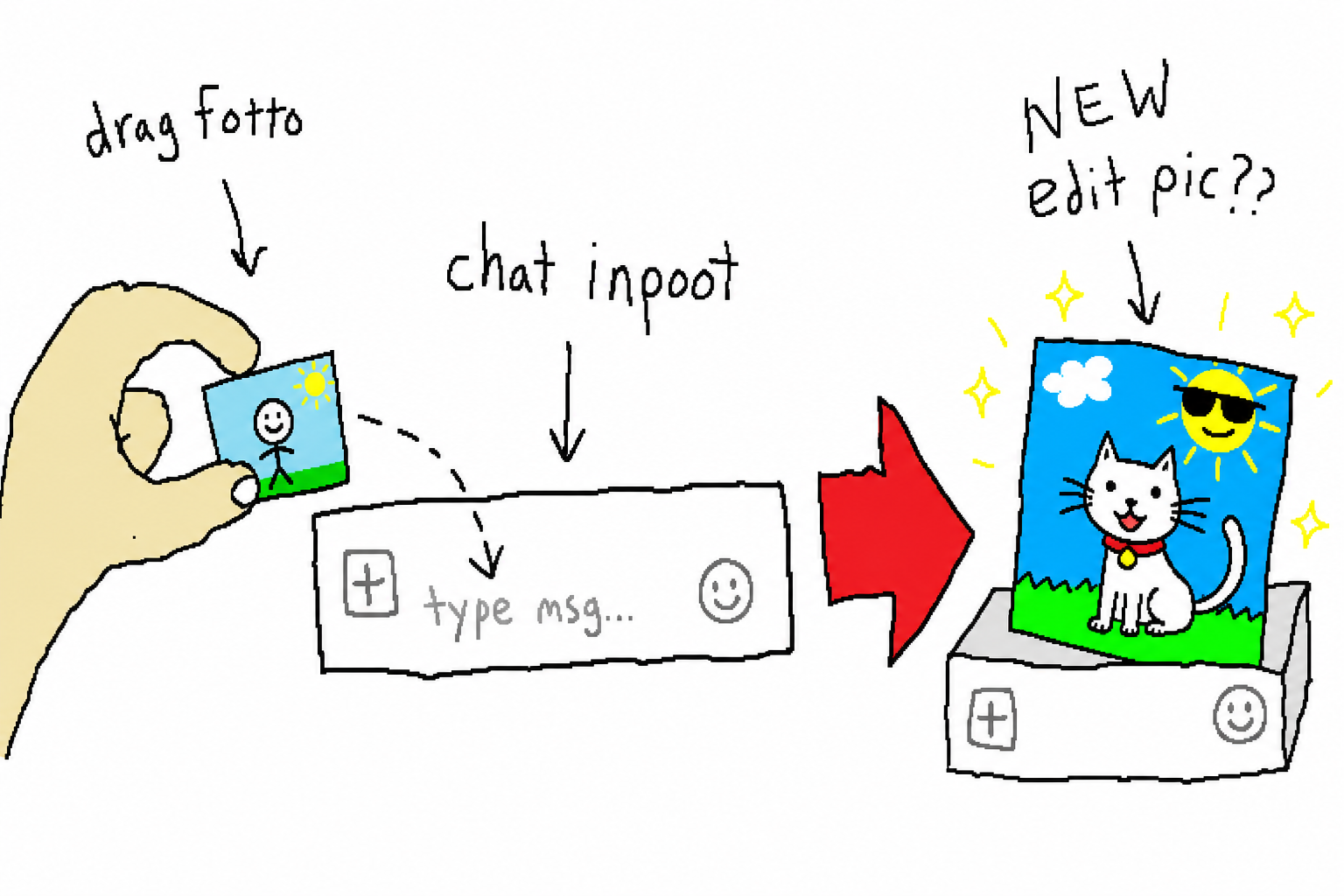
5. 画像から画像へ:参考画像を1枚渡す
参考画像(-i)を1枚渡すと、ゼロから描くのではなく**画像を編集**します——画像を ChatGPT の入力欄にドラッグして、描き直してもらうのと同じです。2つのバックエンドはそれぞれ実装が異なります:
- web:参考画像を
chrome-use upload経由で composer の標準<input type="file">に注入し、それから編集指示を送ります——サイトごとの適配はゼロ、Codex の枠も消費しません; - codex:参考画像を
input_imageのコンテンツブロックとしてリクエストに詰め、画像ツールを強制的に発火させます。
# logo をサイバーパンクなネオン看板に変える
chatgpt-imagegen "これをサイバーパンクなネオン看板にして" -i logo.png -o neon.png
ちょっと面白い仕組みの落とし穴:「生成されたその画像」をどう見分けるか
web バックエンドは実際のページを操作しているので、DOM から生成画像を見つけ出す必要があります。ここには直感に反するポイントが3つあります:
- 新版 ChatGPT の画像は
backend-api/estuary/contentを通り、もう古いoaiusercontentではありません; - 画像から画像のとき、アップロードした**参考画像はユーザーの吹き出し内に全く新しい src で再表示されます**——うっかりすると「自分がアップロードした元画像」を結果として取ってしまいます;
- 生成画像は**独立した画像カード**で、アシスタントメッセージの要素には包まれていません。
したがって正しい判定は:<main> の中で画像ホスティングのドメインに一致する新しい画像を探しつつ、ユーザーの吹き出しに属する画像はすべて除外することです。

6. agent のために生まれた設計思想
これらの原則をつなげると、このプロジェクトの設計方針はこうなります:
- 単一ファイル・ゼロ依存・純標準ライブラリ——agent が持ってくればそのまま動き、
pip installも、仮想環境も、常駐プロセスもありません; - skill としてインストール可能——
npx skills add leeguooooo/chatgpt-imagegen -gにより、Claude Code / Codex / Cursor などから直接呼び出せます; - デフォルトで節約——auto モードは優先して計量されない web を使います;本当に速さが必要なとき、またはヘッドレス環境では codex を使います;
- 結果はワークスペースへ保存——agent が受け取るのは保存済みのファイルパスで、そのまま repo に入ります;
- 会話を自動アーカイブ——web バックエンドは、毎回の画像生成の会話を ChatGPT Project(デフォルトは
imagegen)に分類し、あなたの履歴を汚しません。
一言でいうと:これは人間向けの画像ツールに CLI をかぶせたものではなく、「agent が自分で足りない資源を作る」ことのために、最初から設計されたものです。
7. 上手
# skill として(おすすめ、agent 用)
npx skills add leeguooooo/chatgpt-imagegen -g
# または独立 CLI(依存ゼロ、単一ファイル)
git clone https://github.com/leeguooooo/chatgpt-imagegen
あとはあなたの agent に「README 用の hero 画像を描いて」と一言いえばOK——残りは agent が自分でやります。
ツール repo:chatgpt-imagegen | 裏側のブラウザ自動化エンジン:chrome-use。
余談:この記事に出てくる、あえてヘタに描いた落書き風の原理図と、上にある数枚の**見栄えのいい**サンプル画像は、全部このツール自身が出力したものです。ヘタなのは説明スタイルで、きれいなのはその本当の実力——このギャップそのものが、いちばん良いデモになっています。
コメント
コメントは即時公開されますが、ポリシー違反時は非表示になる場合があります。